- Before you start solving your analytics use case, ask yourself – how significant the change will be for the business if you get the perfect answer to your question. If the change is not significant enough don’t even bother to start solving it.
- The objective of your project should be a business problem or a strategic solution. If you see yourself solving a tactical or IT problem, remember you are impacting the means to an end but not the end.
- Decide what you want to do – assign a weight age to a factor customer already knew about or give insight on a factor customer didn’t knew affects his business. For example, while doing analytics on student’s attendance, an insight for the former case would be – whenever it rains the student’s attendance drops by 27 %.Here the school always knew, rain has an adverse effect on the attendance but they never knew it was 27 %.(This can appear as contradicting to point 2, but for some cases that is what specifically asked by the customer. But whenever possible try avoiding it.)For the latter case it would be whenever there is a bank holiday student’s attendance will be negatively affected. This is something the school never knew about.
- Always make sure you ask your customers deviation percentage to the actual business value that can be considered as prediction success. Because as good as your analytics may be, you will never be able to capture all the influencing factors affecting his business numbers. For example – The customer can say ‘if your predicted sales is 5% on either sides of my actual sales I will consider it as correct.’
- While doing analytics for your customer, whenever possible, try avoiding giving your insight as an absolute value .Because no matter how many factors you may have included in your analysis, there will always be those unknown ones, which can turn your prediction wrong. Rather try to rank the factors influencing customers business based on their influence. The business thus can plan better what to concentrate on as priority.
- Ask the customer what is the offset of an event. Means what is the lag between an event occurring and its results getting reflected. For example an ad campaign being launched and the timeline around which the sales gets lift may have an offset of 2 months among them. This changes from product to product, depending on the factors and results. For some it may even be instantaneous.
- Try to understand from your customer what does significant change means to him. A value may be significant change to one customer but not to another.
- Don’t try to pick the use case, pick a use case. When you are talking to the business, let the business choose the use case for you. Just provide them the below matrix.
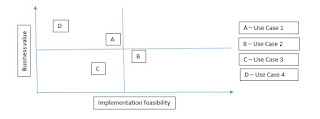
- Whichever use case you choose to implement will have multiple source systems of data. For most of the cases it’s not possible to include every source system as part of the analytics. To decide which source systems to spend your time on, use the below graph –

- Don’t try to answer all the business questions. Rather try to give insights which will enable the business to ask more questions. No one will know his business more than the business owner.
What I write about
- AI
- machine learning
- ml
- AI & Data
- LLM
- management
- nlp
- AI Architecture
- AI Development
- AI Engineering
- AI System Design
- AI adoption
- AI trust
- Agentic AI
- Data Science
- Generative AI
- MCP
- Production AI
- Software Architecture
- bert
- cognitive analytics
- data analysis
- leadership
- product management
- strategy
- text analytics
- transformer
- AI App Store
- AI Assistants
- AI Industry Insights
- AI Innovation
- AI Integration
- AI Optimization
- AI Proctoring
- AI Recommendations
- AI Strategy
- AI Systems Architecture
- AI Tech
- AI Tools
- AI Trends
- AI deployment
- AI model selection
- AI success
- AI workflow orchestration
- API Tuning
- AWS
- Actionable AI
- Adaptive Agents
- Amazon
- Artificial Intelligence
- AutoGen
- Automation
- Autonomous Agents
- Azure
- Azure Cognitive Services
- Azure Document Intelligence
- Batch Processing
- Big Data
- BusinessAndBeyond
- Cheating Detection
- Cloud Solutions
- Collaborative Agents
- Contract Renewal
- Conversational AI
- Coordinated Agents
- CrewAI
- Data Processing
- Data to Wisdom
- Digital Transformation
- Discipline
- Dlib
- Eye Tracking
- Facial Landmark Detection
- Fair AI
- Flask
- Future of AI
- Future of Work
- Gemini
- GenAI
- Human-AI Collaboration
- Human-AI Interaction
- IIMLucknow
- Innovation
- John Nash
- John von Neumann
- LLM model size
- LLM systems
- LOI
- LangChain
- LangGraph
- Learning Agents
- LlamaIndex
- ML engineering
- Machine Learning Systems
- Mediapipe
- OCR
- OpenCV
- PO
- POS analysis
- Patience
- Perceptive Agents
- Personalization
- Personalized AI
- Planning Agents
- Post-Implementation
- Preprocessing
- Product Innovation
- Project Execution
- Proposal Evaluation
- Python Project
- RAG frameworks
- RAG systems
- RFI
- RFP
- Reactive Agents
- Real-time Monitoring
- Role-Based Agents
- SOW
- Safe AI
- SelfGrowth
- Semantic Kernel
- Sentiment Score
- SiddharthaWisdom
- Smart Assistants
- Speech Recognition
- Speed Optimization
- Strategic Agents
- Technology Evolution
- ThinkingWaitingFasting
- Toolchains
- Universal Protocol
- Vendor Performance Review
- agentic AI frameworks
- analytics
- bias
- brain
- brand identity
- brand messaging
- branding templates
- business
- competition
- copilt
- core competency
- covid
- customer targeting
- databricks
- ecommerce
- economics
- economy
- financial
- game theory
- go to market
- gpt
- human
- hyper optimization
- investment
- marketing strategy
- mlflow
- model context protocol
- multi-agent AI systems
- netflix
- performance optimization
- positioning statement
- predictive modelling
- product owner
- product positioning
- reasoning cost latency
- recommendation engine
- roi
- scalable AI
- squad
- startup branding
- strategy. consultation
- streaming
- system design
- tableau
- tool orchestration
- value proposition
- vizualization
Sunday, 5 July 2015
10 THINGS TO KEEP IN MIND FOR AN ANALYTICS PROJECT


Wednesday, 18 February 2015
HADOOP – HOT INTERVIEW QUESTIONS - What is the responsibility of name node in HDFS?
- Name node is the master daemon for creating metadata for blocks stored on data nodes.
- Every data node sends heartbeat and block report to Name node.
- If Name node does not receive any heartbeat then it simply identifies that the data node is dead. The Name node is the single point of failure. Without Name node there is no metadata and the Job Tracker can’t assign tasks to the Task Trackers.
- If Name node goes down HDFS cluster in inaccessible. There is no way for the client to identify which data node has free space as there is no metadata available in the data node.
Saturday, 12 July 2014
Bit level SQL coding for database synchronization
Abstract
Client X has an ERP system with a master module and several
instances of its client installed across the Globe. The business requires all
the client instances to be in sync with the master with exceptions. The way to
achieve that was to keep the metadata of the instances, stored in the system
databases of the client and master in sync. One way of doing that was to
restrict the users from making changes to the client or run synchronization
scripts at regular intervals to sync the master and clients.
Introduction
The objective of the project was to ensure that all client
databases are using a group standard set of data in key tables. It also allows
client databases to set certain local persisted fields whist blocking changes
to other fields. The way to achieve that was to develop Triggers on the local
tables to enforce the business rules. And
in cases where it does not stop
local users with DBA access from being able to disable the triggers and update
the synchronized data, develop stored procedures run every night to overwrite
and persist the group data standards.
So the solution designed was:
The target implementations were:
Client Synchronization Triggers
o
SQL Triggers on the database to enforce the
business logic by allowing or preventing changes to the synchronized data
Master Audit Triggers
o
SQL Triggers on the database will track any
changes made to the synchronized tables
Synchronization Scripts
o
SQL scripts contain the business logic and
will copy the necessary values from the tables in the GBLDEVALLSynchronisation
schema to the Production tables.
Problem
Definition
One such requirement for us was to check whether the setting
options applied in clients where in sync with the master. Each of the setting
options were applied through check boxes.
When we check the metadata tables we found out all the
setting options were defined as a screen within a column value in a table with
each setting option represented by a bit.
Now the users were allowed to make changes to certain
settings, while prevented from changing others.
So our job was to search for bits at particular positions
within the string and preventing the user to change those bits from 1 to 0 or
vice-versa. If in case someone with
administrator privilege disables the trigger and change the restricted values,
then run scripts at night to search for those bits and compare their values
between master and clients, and in case difference reverting back the client’s
value.
High Level
Solution
For us there were
two deliverables:
- Triggers-To restrict the users from making changes.
- Synchronization script-In case someone makes the change, identifies the change and revert it.
Since
it was a bitwise operation the operators available to us were
- &(bitwise AND)
- |(bitwise OR)
- ^(bitwise exclusive OR)
The
challenges we faced were
- Searching for bits at particular positions.
- Turning on or off a bit if a mismatch is found.
Solution
Details
Let
us try to explain the solution we implemented for the trigger. Let’s take an
example for the bit position – 256.The meaning of this requirement is value at
the bit position 256 should be same for the client and master, whereas the
value for the other bit positions may be different. In other words the client is
not allowed to change value at the 256 bit position while they can change the
value at other bit positions.
Let’s
consider the master has hexadecimal value – 421, binary value – (110100101).
And the
client tries to change it to hex value of 165, binary value – (010100101).
So
the result should be, it should throw an error.Beacuse the value at the 256 bit
position is different. Though the values at the other positions are different
it should not matter.
So
the solution we came up with is applying & (Bitwise AND) the values with
bit position we are searching for and comparing the values.
[
Example
of how & (Bitwise AND) works.
(A & B)
0000 0000 1010 1010
0000 0000 0100 1011
-------------------
0000 0000 0000 1010
]
For
Master - 421 & 256 = 256.
i.e.
110100101 & 100000000 = 100000000.
For
Client – 165 & 256 = 0
i.e.
010100101 & 100000000 = 000000000
Since
the values are different it throws an error.
Let’s
take another example –
The
master has hexadecimal value – 420, binary value – (110100100).
And
the client tries to change it to hex value of 421, binary value – (110100101).
So
the result should be, it should not throw an error.Beacuse the value at the 256
bit position is same. Though the values at the other positions are different it
should not matter.
For
Master - 420 & 256 = 256.
i.e.
110100100 & 100000000 = 100000000.
For
Client – 421 & 256 = 256
i.e.
110100101 & 100000000 = 100000000
Since
the values are same it does not throw an error.
Now
let’s try to explain what we did for the stored procedure. The purpose of the
stored procedure is to turn on or off the value if a standard value has been
changed by the client which he is not allowed to do.
Let’s
consider the same example of the value being changed at 256th
position.
Note
there are two parts to it.In case the client has changed the value at 256th
position to 1 we need to revert it back to 0 and in case the client has changed
it to 0 we need to revert it back to 1.
The
challenge was to achieve the toggle function.
Part
1 -
Now
let’s consider a value of 111001010 which in hexadecimal is 458.
[
Example
of how Bitwise Exclusive OR works
(A ^ B)
0000 0000 1010 1010
0000 0000 0100 1011
-------------------
0000 0000 1110 0001
]
The
function we came up with to achieve the toggle function is:
(The
number ^ the position) & 67108863.
So
for our example:
(458
^ 256) & 67108863
Or
(111001010 ^ 100000000) & 11111111111111111111111111
=
011001010.
Part
2 -
Now
let’s consider a value of 1011000110 which in hexadecimal is 710.
So
the underlined value at the 256th position is 0 and it needs to be
toggled to 1.
[
Example
of how Bitwise Exclusive OR works
(A ^ B)
0000 0000 1010 1010
0000 0000 0100 1011
-------------------
0000 0000 1110 0001
]
As
mentioned before the function for toggling is:
(The
number ^ the position) & 67108863.
So
for our example:
(710
^ 256) & 67108863
Or (1011000110
^ 100000000) & 11111111111111111111111111
= 1111000110.
Hence
we achieved our toggling function.
We
took 67108863 as the value since for us the highest position required for
toggling is 33554432 and our value is next higher to it.So we made sure we
covered our requirement.
Solution Benefits
With our deliverable s we achieved the objective of ensuring that all client databases are in sync with the master and are using a group standard set of data in key tables. It blocked changes to protected fields while allowing clients to change certain local persisted fields.
While along with it, it took care of the following key considerations:
· The process does not cause heavy network traffic and is as optimized as possible
· The process is able to handle different versions of Viewpoint
· The process is able to enforce the business logic (i.e. prohibit local changes from being made to synchronized fields that are NOT persisted)
· The process is updateable to handle changing business logic
· The process only updates ViewPoint tables during a specified time window
· The process is fully auditable
· The process facilitates a full DTAP lifecycle
While along with it, it took care of the following key considerations:
· The process does not cause heavy network traffic and is as optimized as possible
· The process is able to handle different versions of Viewpoint
· The process is able to enforce the business logic (i.e. prohibit local changes from being made to synchronized fields that are NOT persisted)
· The process is updateable to handle changing business logic
· The process only updates ViewPoint tables during a specified time window
· The process is fully auditable
· The process facilitates a full DTAP lifecycle
Solution
extend-ability
As
next set of steps we would include the auditing functionality and it would be
fully automated. The design and functionality details are mentioned below:
Master Audit Triggers
Overview
The master audit triggers will be used to audit any changes
made to the synchronized tables in the Group ViewPoint Master database.
Auditing strategy
Let’s consider the following example.
A table SUPPLIER_MSTR exists as:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
123
|
ABC
|
Acme
Supply Co
|
Manchester
|
A corresponding table SUPPLIER_MSTR_AUDIT for it exists as:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
User
|
Event_Type
|
Event_DateTime
|
123
|
ABC
|
Acme
Supply Co
|
Manchester
|
Alan.Donald
|
Insert
|
23-2-2012
10:15 AM
|
It tells us John created this record on 23rd Feb
2012 as 10:15 AM.
Now this morning I changed it to –
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
123
|
ABC
|
Acme
Supply Co
|
London
|
SUPPLIER_MSTR will show no history and will show the current
scenario.
So SUPPLIER_MSTR_AUDIT table will be now –
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
User
|
Event_Type
|
Event_DateTime
|
123
|
ABC
|
Acme
Supply Co
|
Manchester
|
Alan.Donald
|
Insert
|
23-2-2012
10:15 AM
|
123
|
ABC
|
Acme
Supply Co
|
London
|
Anirban.Dutta
|
Update
|
21-6-2013
12:46 PM
|
Another record added.
SUPPLIER_MSTR:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
123
|
ABC
|
Acme
Supply Co
|
London
|
124
|
XYZ
|
Worlds
Greatest Retailer
|
Leeds
|
SUPPLIER_MSTR_AUDIT:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
User
|
Event_Type
|
Event_DateTime
|
123
|
ABC
|
Acme
Supply Co
|
Manchester
|
Alan.Donald
|
Insert
|
23-2-2012
10:15 AM
|
123
|
ABC
|
Acme
Supply Co
|
London
|
Anirban.Dutta
|
Update
|
21-6-2013
12:46 PM
|
But David came and deleted the first record.
SUPPLIER_MSTR:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
124
|
XYZ
|
Worlds
Greatest Retailer
|
Leeds
|
SUPPLIER_MSTR_AUDIT:
Supplier_Key
|
Supplier_Code
|
Supplier_Name
|
Supplier_State
|
User
|
Event_Type
|
Event_DateTime
|
123
|
ABC
|
Acme
Supply Co
|
Manchester
|
Alan.Donald
|
Insert
|
23-2-2012
10:15 AM
|
123
|
ABC
|
Acme
Supply Co
|
London
|
Anirban.Dutta
|
Update
|
21-6-2013
12:46 PM
|
124
|
XYZ
|
Worlds
Greatest Retailer
|
Leeds
|
Anirban.Dutta
|
Insert
|
21-6-2013
12:50 PM
|
123
|
ABC
|
Acme
Supply Co
|
London
|
Arron.Lennon
|
Delete
|
21-6-2013
12:53 PM
|
Audit table structures
Each table will have its own
audit table.
The AUDIT tables will replicate
the actual table along with few extra columns.
The extra columns being.
User nvarchar(100)
Event_Type nvarchar(50) only
(‘Insert,’Update’,’Delete’ should be allowed).
Event_DateTime DateTime.
Stored Procedure run status logging
We are planning to capture the
run status of a SP with the following table structure.
SchemaName nvarchar(100),
StoredProcedure nvarchar(128),
UserName nvarchar(100),
StartTime datetime,
EndTime datetime,
EventStatus nvarchar(500),
ReasonForFailure nvarchar(max)
The granularity of the information capture will
be object level.
For example:
If we assume a four Stored Procedures to be
loading four tables:
COAAccount
COAHeader
DMIxFields
EntityTypes
Then the corresponding entries in
the table would be :
SchemaName
|
StoredProcedure
|
UserName
|
StartTime
|
EndTime
|
EventStatus
|
ReasonForFailure
|
GBLDEVALLSECCO
|
USP_SynchroniseCoaAccount
|
Anirban.Dutta
|
1:15:0010 PM
|
1:15:0017 PM
|
Success
|
|
GBLDEVALLSECCO
|
USP_SynchroniseCoaHeader
|
Anirban.Dutta
|
1:15:0018 PM
|
1:15:0025 PM
|
Success
|
|
GBLDEVALLSECCO
|
USP_SynchroniseDmixfields
|
Anirban.Dutta
|
1:15:0019 PM
|
1:15:0022 PM
|
Success
|
|
GBLDEVALLSECCO
|
USP_SynchroniseEntityTypes
|
Anirban.Dutta
|
1:15:0023 PM
|
1:15:0026 PM
|
Success
|
Deliverables
1.
Stored Procedure code.
2.
Trigger code.
Conclusion
The above solution was provided by using/extending VP MDT to
copy the synchronized tables from Group ViewPoint Master to each client
database during the VP change window, then using stored procedures run every
night to overwrite and persist the group data standards.
Triggers were added to the Group ViewPoint Master for audit
purposes as well as being required on the local tables to enforce the business
rules.
Subscribe to:
Comments (Atom)
- BIaaS plus Cloud Computing
- HADOOP – HOT INTERVIEW QUESTIONS - What is the responsibility of name node in HDFS?
- Artificial Intelligence - Man vs Machine
- BI on Cloud - Service overview and types of vendors
- Why Foreign Keys are now foreign to current DWBI applications
- Future Trends in IT
- Bit level SQL coding for database synchronization
- 10 THINGS TO KEEP IN MIND FOR AN ANALYTICS PROJECT
- EMI – The dream killer – an Indian software engineer's perspective.
- What is Kerberos ?
AI Model Size Selection: Trade-off Between Reasoning, Cost, and Latency
AI Model Size Selection: It’s a Trade-off Between Reasoning, Cost, and Latency When people talk about AI models, the convers...
